FederatedScope-GNN: Towards a Unified, Comprehensive and Efficient Package for Federated Graph Learning
KDD2022上的介绍:
https://dl.acm.org/doi/abs/10.1145/3534678.3542631

https://joneswong.github.io/KDD22FLTutorial/
227页PPT-PDF链接:
https://joneswong.github.io/KDD22FLTutorial/materials/slides.pdf
3.论文核心作者解读:

上集
https://www.bilibili.com/video/BV1X14y187Bp
下集
https://www.bilibili.com/video/BV1W24y1977x
10/23/2022 11:01:54 AM
以作者讲述的PPT为FederatedScope-GNN的内容部分,277页PPT做为概念补充,论文本体作为内容补充,描述清楚论文提出的目的/实际意义(论文);实验部分不展开,讲清相关有意思的概念(227页PPT);说出实验的结论(作者讲述)。 - -10/30/2022 6:18:37 PM

227页PPT:联邦学习的实用介绍



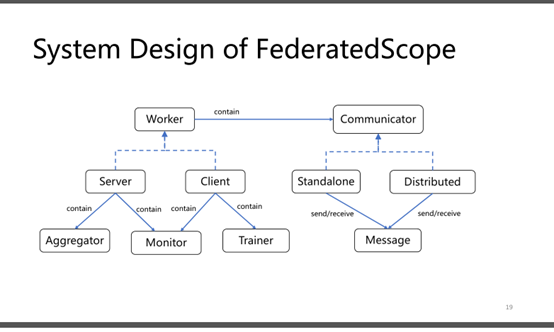
整体框架-系统涉及

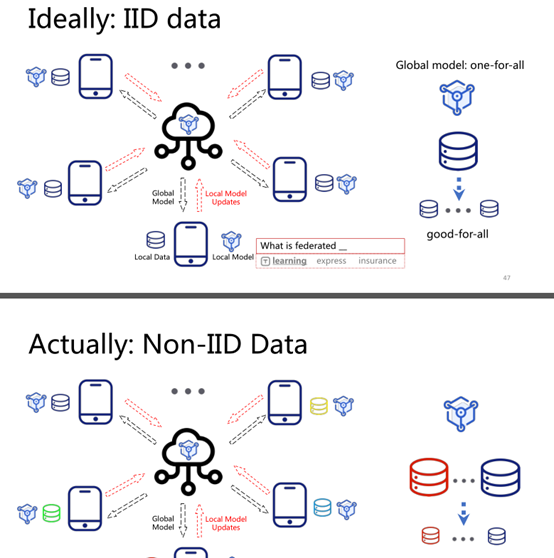
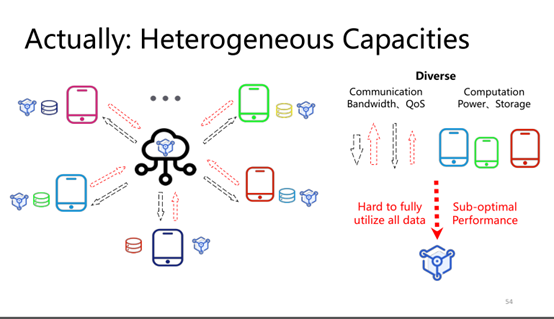
很贴切的现实与理想的差距
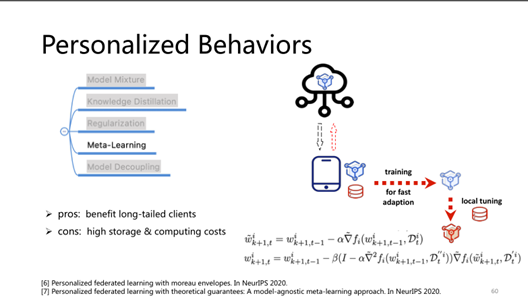
所谓长尾问题:

https://zhuanlan.zhihu.com/p/127791648

提供丰富的评判标准方法引用及 PFL性能比较,评估,并指出潜在进一步的研究性

从第100页开始,应仔细看
- 场景描述
- 联邦图学习面临的挑战


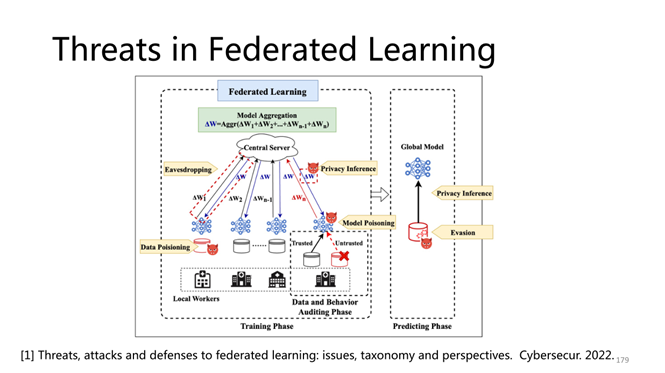
此图很66666

描述准确

介绍很有意思
可以在联邦学习框架中
模拟这些攻击,以检验算法的隐私保护性

新的防御手段
-------
侧重使用介绍,描述清楚基础概念,介绍一下这个框架他的商业思路!
10/29/2022 8:51:51 PM
明早—1.看一遍原文
,利用别的颜色的字,补充
2. 下午看一遍视频讲解,再次补充
FederatedScope-GNN: Towards a Unified, Comprehensive and
Efficient Package for Federated Graph Learning
FederatedScope-GNN:面向统一、全面和高效的联邦图学习包

引用许可:学习/课堂:讲述

graphdatazoo和modelzoo?????
摘要:
联邦学习(FL)的不可思议的发展使计算机视觉和自然语言处理领域的各种任务受益,而现有的框架如TFF和FATE使得在现实应用中部署更加容易。然而,联邦图学习(FGL)虽然图数据很流行,但由于其独特的特性和需求,并没有得到很好的支持。FGL相关框架的缺乏增加了完成可重复研究和在现实应用中部署的努力。
基于这个强烈的需求,本文进行了如下的工作:
-
我们首先讨论创建一个易于使用的FGL包时将面临的挑战,并相应地介绍我们实现的包FederatedScope-GNN (FS-G):
-
为FGL算法的模块化和表达提供一个统一的视图
-
comprehensive DataZoo and ModelZoo for out-of-the-box FGL capability;
-
一个高效的模型自动调优组件
-
现成的隐私攻击和防御能力
-
-
通过大量实验
-
验证FS-G的有效性
-
同时为社区获得了许多关于FGL的有价值的见解。
-
此外,我们在真实的电子商务场景中使用FS-G为FGL应用程序提供服务,在这些场景中取得的改进表明了巨大的潜在业务收益。
-
公开发布FS-G以促进FGL的研究,并使由于缺乏专用软件包而无法实现的广泛应用成为可能(基于阿里的框架)。
-
CCS CONCEPTS
https://www.zhihu.com/question/278822945
关键词:联邦学习 图神经网络
介绍-introduction
随着人们对隐私问题的日益关注,联邦学习(FL)[28]作为一种无需访问分散数据的协同学习模型范式,越来越受到业界和学术界的关注。它成功的应用包括键盘预测[12],物体检测[26],语音识别[29],等等。这一惊人的进展得益于FL框架,例如TFF[5]和FATE[40],它们将从业者从实现细节中解放出来,并促进了从研究原型到部署服务的转换。(which save practitioners from the implementation details and facilitate the transfer from research prototype to deployed service.)
然而,这些有用的支持主要集中在视觉和语言领域的任务上。然而,在现实应用中无处不在的图表数据,如推荐系统[36]、医疗保健[42]和反洗钱[33],还没有得到很好的支持。作为一个证据,大多数现有的FL框架,包括TFF、FATE和PySyft[43],都没有提供现成的联邦图学习(FGL)能力,更不用说在视觉和语言任务中缺乏与LEAF[6]相同的FGL基准了。
因此,包括FedAvg[28]、FedProx[23]和FedOPT[1]在内的FL优化算法主要在视觉和语言任务上进行评估。当应用于图神经网络(GNN)模型优化时,其特性尚不清楚。缺乏专用框架支持的另一个后果是,许多最近的FGL工作(例如,FedSage+[42]和GCFL[37])不得不从头实现他们的方法,并在各自的测试平台上进行实验。
我们注意到,缺乏广泛采用的基准和相关工作的统一实现已经成为开发新的FGL方法并在现实应用中部署的障碍。它增加了工程工作,更严重的是,引入了进行不公平比较的风险。(It increases engineering effort and, more seriously,
introduces the risk of making unfair comparisons)
实际需求/商业定位:迫切需要创建一个FGL包,它可以节省从业者的工作,并为完成可重复研究提供一个测试平台。
论文工作/贡献:
①我们指出了之前的FGL框架缺少什么特性,②以及应对这些需求将所需面对的挑战:
-
模块化的统一视图及灵活编程
-
相比于FL的每轮次计算,FGL通常需要在参与者之间交换多个异构数据(例如,梯度、节点嵌入、加密邻接表等)
-
除了普通的本地(局部)更新/全局聚合外,FGL的参与者还拥有丰富的子例程来处理这些异构数据
-
FL算法通常在大多数现有框架中通过声明一个静态计算图来表示,这促使开发人员关心如何协调这些数据交换的参与者。
因此,FGL包应该为开发人员提供一个统一的视图,以轻松地表示这种异构的数据交换和各种子例程,允许灵活地对丰富的行为进行模块化,从而方便地实现FGL算法。
-
-
Unified and Comprehensive Benchmarks
-
由于隐私问题,真实世界的FGL数据集非常罕见。大多数之前的FGL工作都是通过拆分一个独立的图数据集来进行评估的。没有统一的拆分机制,它们基本上只能使用各自的数据集
-
同时,它们的GNN实现并没有对齐并集成到同一个FL框架中。
所有这些都增加了相关工作不一致比较的风险,促使FGL包建立可配置的、统一的和全面的基准测试。
-
-
高效和自动化的模型调优
-
大多数联邦优化算法还没有在GNN模型中得到广泛的研究。因此,在FL设置下,从业者往往缺乏适当的先验来调优他们的GNN模型,这使得进行超参数优化(HPO)是不可避免的。
-
由于执行整个FL课程[18]的巨大成本,直接将通用HPO工具包集成到FL框架中无法满足效率要求
-
即使是一个单一的模型被完美地调谐,普遍的非i.i.d联邦图数据的仍然可能导致性能不理想。
. In this situation, monitoring the FL procedure to get aware of the non-i.i.d.ness and personalizing (hyper-)parameters are helpful for further tuning the GNN models.
-
-
隐私攻击与防御
-
对FL算法进行隐私攻击是检验FL过程是否存在隐私泄露风险的一种直接有效的方法,然而没有现成FL框架做到这一点
-
与一般的FL框架相比,除了共享全局模型的梯度外,FGL还可以在客户端之间共享额外的图相关信息,如节点嵌入和邻居生成器
在不验证共享这些信息的安全性的情况下,FGL的应用仍然存在问题。
-
②本文所提及的FS-G开发包是如何应对如上挑战的?
-
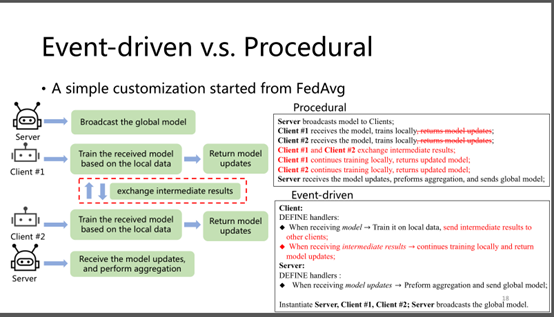
选择在事件驱动的FL框架FederatedScope[38]上构建FS-G
-
该框架将交换的数据抽象为消息,并通过定义消息处理程序来描述每个参与者的行为
-
开发FGL算法的用户可以简单地定义(异构)消息和处理程序,消除协调参与者的工程开销
Meanwhile, different handlers can be implemented with respective graph learning backends(不同的后端程序实现) (e.g., torch_geometric and tf_geometric).
-
-
为方便对相关的FGL方法进行基准测试
-
FS-G提供了一个GraphDataZoo,它集成了一组丰富的拆分机制,适用于大多数现有的图数据集
-
还提供了一个GNNModelZoo,集成了许多最先进的FGL算法
-
It is worth mentioning that we identify a unique covariate shift of graph data that comes from the graph structures, and we design a federal random graph model for the corresponding further study.(没懂)
-
集成对数据集的预处理及现有算法,方便针对FGL算法的研究,而不困扰于预处理,现有算法则可以进行对比分析
-
FS-G提供了一个用于调优FGL方法的组件。
-
它提供了实现低保真HPO的基本功能,使FS-G的用户能够将现有的HPO算法推广到FL设置
-
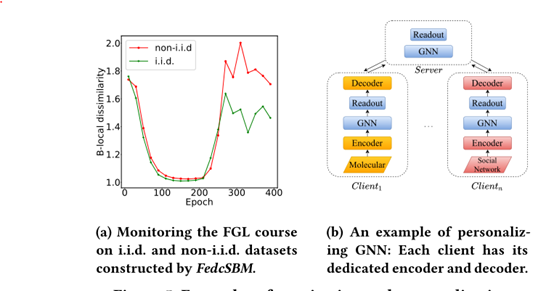
当单一模型不足以处理非non-i.i.d.图数据,组件提供了丰富的度量来监视客户机之间的不同,并提供了一个参数分组机制,以统一的方式描述各种个性化算法。
-
-
考虑到FGL中交换的额外异构数据,演示在各种攻击下隐私泄露的程度并提供有效的防御策略。FS-G包括一个专门的组件,提供各种现成的隐私攻击和防御能力,这些功能封装为FGL过程的插件功能。
具体验证与实践:
-
对FS-G进行了广泛的实验研究,以验证其实施正确性,验证其有效性,更好地了解FGL的特性。
-
使用FS-G服务于三个真实的电子商务场景,协同学习的GNN优于本地学习的GNN,这证实了FS-G的商业价值。
-
提供了开源的FS-G,论文作者相信这可以简化FGL算法的创新,促进它们的应用,并使更多现实世界的业务受益。(其自身利益:来使用阿里的平台吧,以及为后续的统一性框架标准做贡献)
相关工作
-
联邦学习(作为分布式学习的一种特殊情况,优化算法是该算法的核心研究课题)中:……..
-
联邦图学习:相较于FL,FGL表现出新的特性
-
在FL设置下处理与图相关的任务时,出现了几个独特的算法挑战,例如,完成跨客户端边缘[42],处理异构图级任务[37],增加每个客户端的子图[36],并在客户端[30]之间对齐实体。…….
-
-
FL软件
-
大多数现有FL框架被设计为传统的分布式机器学习框架:
-
其中计算图被声明并为参与者分割,然后每个特定部分由相应的参与者执行。
-
用户通常必须通过声明性编程(例如,描述计算图)来实现他们的FL算法,这提高了开发人员的门槛。在满足FGL方法的独特需求时,这个可用性问题加剧了。
-
因此,大多数现有的FL框架没有对FGL的专门支持,实践者不能毫不费力地在它们之上构建FGL方法。
-
一个例外是FedML[14],它是建立在事件驱动架构上的第一个FL框架之一,提供了一个FGL包FedGraphNN[13]。
-
然而,他们仍然专注于具有简单和规范行为的FGL算法。许多有影响力的FGL工作还没有整合,包括上面讨论的那些。
-
此外,他们忽视了对FGL算法进行有效的GNN模型调优和隐私攻击与防御的要求,这在实践和研究中都是至关重要的。
-
-
INFRASTRUCTURE 基础架构
概述:
-
FS-G的核心是一个事件驱动的FL框架FederatedScope[38],它具有基本的实用程序(即构建FL过程),并且它与各种图学习后端兼容。
-
因此,我们在FederatedScope上构建了我们的GNNModelZoo和GraphDataZoo,在表达学习过程方面具有最大的灵活性,对联邦工作人员(例如,协调参与者)的关心最少。
-
我们设计了Runner类作为一个方便的接口来访问FGL执行,它统一了模拟和分布式模式。
-
FS-G提供了一个用于性能优化的自动模型调优组件和一个用于隐私攻击和防御的组件。
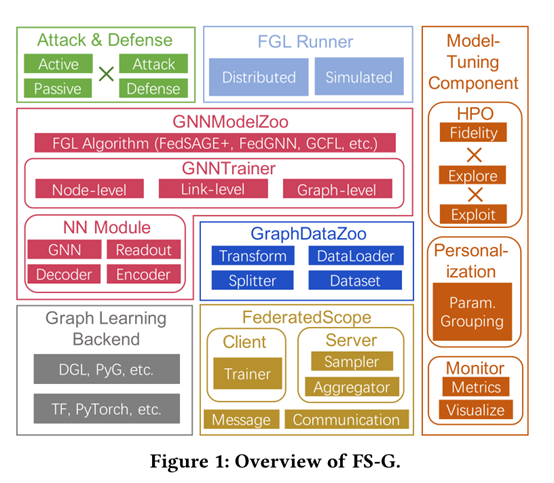
详细介绍上图:
-
联邦图学习的要求
-
基于FederatedScope的开发
具体不展开了
4 GRAPHDATAZOO
一个全面的GraphDataZoo为FGL提供一个统一的测试平台是必不可少的。为了满足不同的实验目的,我们允许用户通过配置数据集、拆分器、转换和数据加载器的选择来组成FL数据集。
按照惯例,Transform类负责将每个图映射到另一个图,例如,作为节点属性增加节点度。Dataloader类设计用于遍历图集合或从图中采样子图。我们将在本节中详细介绍Splitter类和Dataset类。
Splitting Standalone Datasets-为了通过现有的独立图形数据集模拟联邦图形数据集(拆分现有独立数据集的策略)
New Federated Learning Datasets从其他真实世界的数据源或联邦随机图模型构建了三个联邦图数据集:
FedDBLP:最新的DBLP转储创建这个数据集,其中每个节点对应于一篇已发表的论文,每条边对应于一篇引文(异质引文网络DBLP数据集)
Cross-scenario recommendation (CSR):根据从电子商务平台收集的用户-商品交互创建这个数据集
FedcSBM:图数据由属性模式和结构模式组成,但之前的联邦图数据集并没有解耦这两个方面的协变量移位。因此,我们提出了一个基于cSBM[10]的联邦随机图模型FedcSBM。FedcSBM可以生成不同客户机的节点属性遵从相同分布的数据集。同时,客户之间的同质性程度可能不同,因此协变量的变化来自于结构方面。
5 GNNMODELZOO AND MODEL-TUNING COMPONENT
介绍….描述上图,具体没细看
具体参照227PPT讲讲简单概念
5.1 Federated Hyper-parameter Optimization
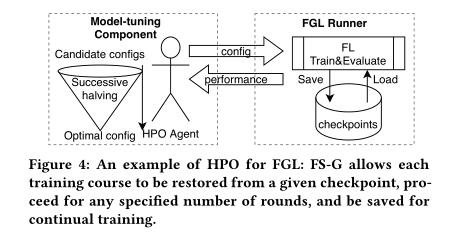
5.2 Monitoring and Personalization
6 OFF-THE-SHELF ATTACK AND DEFENCE ABILITIES
见227PPT
FederatedScope的隐私攻击与防御组件集成了各种现成的被动隐私攻击方法,包括类代表推理攻击、成员推理攻击、属性推理攻击以及训练输入和标签推理攻击。这些方法被封装为GNNTrainer的可选钩子。一旦用户选择了一个特定的钩子,在训练过程中,GNN模型和目标数据的一些所需信息将自动输入到钩子中。除了之前的被动攻击设置(对手是诚实但好奇的),FS-G还支持恶意对手设置。攻击者可以通过修改消息来偏离FL协议。为了防御被动隐私攻击,FS-G可以利用FederatedScope的插件防御策略,包括差异隐私、MPC和数据压缩。同时,FederatedScope提供信息检查机制,有效检测异常消息,防御恶意攻击。
7. 实验
我们利用FS-G进行了大量的实验,目的是验证FS-G实现的正确性,建立人们长期以来对FGL的需求基准,并对FGL有更多的认识。此外,我们将FS-G部署在真实的电子商务场景中,以评估其业务价值。
7.1关于联邦图学习的广泛研究
在本研究中,我们考虑了三种不同的设置:
(1)Local:每个客户端用其数据训练一个GNN模型
(2) FGL:分别使用FedAvg[28]、FedOpt[1]和FedProx[23]在分散数据上协同训练GNN模型
(3)GLOBAL:在完整数据集上训练一个GNN模型。
通过对各种GNN架构设置及不同任务下的比较,我们打算为FGL建立全面和可靠的基准。
分析 协议+结果分析
-
节点级任务:
-
链路级别的任务:
-
Graph-level任务:
7.2超参数优化研究
在本实验中,我们对联邦学习的 GCN 和 GPR-GNN 进行 HPO,旨在验证我们的模型调整组件的有效性。 同时为 FGL 设置HPO 基准并获得一些新的见解,长期以来一直被遗漏但强烈需要。
采用SHA(见第5.1节)来优化FedAvg学习到的GCN/GPR-GNN的超参数
7.3 Study about Non-I.I.D.ness and Personalization
旨在研究图数据的唯一协变量偏移——不同客户端的节点属性服从相同的分布,但它们的图结构不相同。 同时,我们评估了 FS-G 的模型调整组件提供的个性化是否可以处理这种非 i.i.d.ness。
7.4 在真实的电子商务场景中部署
我们部署 FS-G 服务于一个联邦,三个不同部门运营的电子商务场景。 这些场景包括购买行为前后的搜索引擎和推荐系统。 由于他们都旨在预测每个给定用户是否会单击特定项目,并且他们的用户和项目有大量交叉点,因此共享用户-项目交互日志以训练模型是有希望的,并且一直是他们的解决方案。 但是,这种数据共享会增加隐私泄露的风险,并违反新制定的法规,例如《中国网络安全法》。
如果没有数据共享,每一方都必须在其用户项二分图上训练其模型,从而错过从其他图借力的机会。 考虑到他们图表的规模非常不同,例如,一个场景只有 184,419 次交互,而另一个场景有 2,860,074 次,这可能会严重影响"小"场景的性能。 通过我们的 FGL 服务,这些各方可以协作训练 GraphSAGE 模型来预测每个用户-项目对之间的链接。对其保留日志的评估表明,单独训练的 GraphSAGE 模型的 ROC-AUC 为 0.6209±0.0024,而 FGL 为 0.6278±0.0040,这是一个显着的改进。 值得注意的是,离线 ROC-AUC 评估的微小改进(0.001 级)意味着搜索/推荐/广告的真实点击率预测存在显着差异。 因此,改进证实了 FS-G 的商业价值。
8 结论
在本文中,我们实现了一个 FGL 包 FS-G,以促进 FGL 的研究和应用。 利用 FS-G,FGL 算法可以以统一的方式表达,针对全面统一的基准进行验证,并进一步有效地调整。 同时,FS-G 提供了丰富的插件攻击和防御工具来评估感兴趣的 FGL 算法的隐私泄露程度。 除了对基准进行广泛研究外,我们还将 FS-G 部署在现实世界的电子商务场景中并获得商业利益。 我们将发布 FS-G,从无处不在的图数据中创造更大的商业价值,同时保护隐私。
附录:
-
Details of Off-the-shelf Splitters
-
Details about Our Experiments
-
Datasets description
10/30/2022 11:15:28 AM
总结:看完了全文,我们不去关注具体的算法细节,描述论文整体的框架,依照论文的行文介绍论文,并利用227页PPT补充每节中出现的知识点,具体详细内容则不加叙述,今天下午我们看看论文核心作者的讲解视频,如果知识太过具体,我们则粗略一过,否则,可以具体补充一些概念,在看完视频的基础上,我们可以将论文+PPT内容议结合,视频内容(如果有)一补充,作为整体该论文的读书报告内容。
10/30/2022 11:19:28 AM
视频讲解:


-
联邦学习普遍性能优于单独性的学习,证明了联邦学习确有提升整体性能;此外
联邦学习低于
全局训练(利用完整数据集,不考虑隐私下)的学习性能,标志着联邦学习还有很大的进一步研究空间
-
在联邦学习/单独学习下进行了多种不同GNN的模型训练,最后模型性能优劣排序
联邦学习和单独学习绝大多数情况下是一致的,这里应该是想强调联邦学习具有合理的外推性,而非是联邦架构影响了算法,使得GNN的性能有提升。(两个变量间的相关性是强的,而非受其他干扰的)
-
相对于FedAvg ,一些更复杂的Fancy FL算法并没有在多种GNN/DataSet情况下保持击败FedAvg的一致性,结果是各有优劣
-
在同样的数据集、GNN模型及FL算法下,当使用不同的splitters 来构造出联邦图数据集时,其对应的non-iidness 性质是不一样的;不一样的non-iidness呈现,在对应不一样的数据集、GNN模型及FL算法组合下,他们的性能优劣rank是不太一致的;
也就是说,真正联邦图学习中存在的non-iidness和最终的研究问题应该保持着非常大的关系,所以在仿真/研究中,应该去选择合适的splitters针对现实问题中应存在什么样的non-iidness来
构造对应联邦图数据集的non-iidness
-
我们可以发现,在不同的DATA、GNN及FL算法组合上做实验时,提供了公平的比较)提供了相同的超参搜索空间),看出不同超参配置对性能的影响非常大,特别是涉及到更新步长及learning rate(针对此,提供了一个超参优化组件)
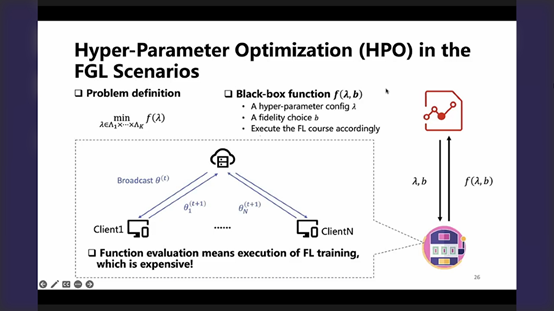
P26- 黑盒评估更为昂贵,一般采用试错的方法
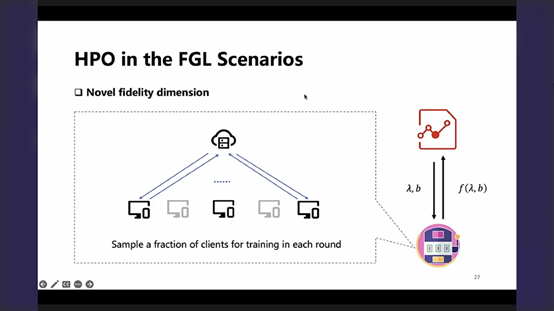
P27-同时FL提供了一个新的保真度维度(采样减少,开销下降),但每轮次采样少,是否真的可以让联邦整体模型学习更"省"(如果增加了轮次?),应具体根据系统去考虑
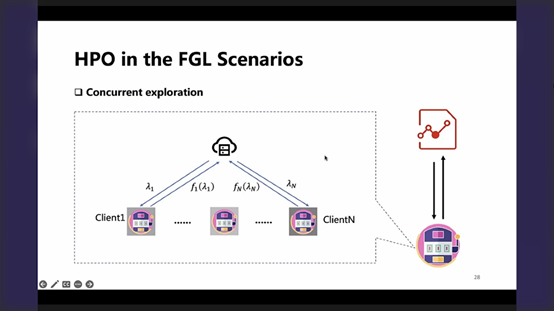
P28-对于在client上做local update step的超参,可以提供一个并发探索的机会,即每一个通信轮次,可以在不同的client上进行不同的超参调整尝试(即并发地进行对超参测试/搜索空间的探索),着也是新近的算法的一个研究方向
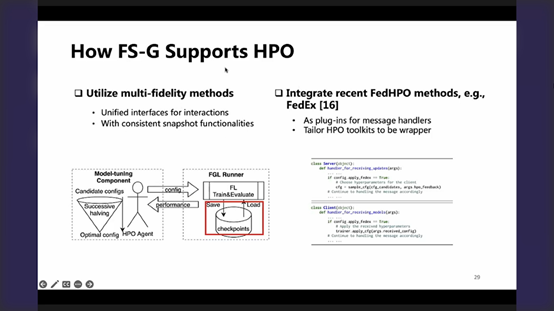
P29-为了更好地支持联邦图下的HPO,做了如下事情:
-
对每一次的函数评估做了抽象 Runner类,很好地封装了联邦课程(左图的两者间规则化的交互接口)
-
在联邦的任意时刻,总把必要的,能够反映联邦课程-真正完整状态的信息保存起来,产生一个checkpoints,并允许读取/恢复,这样的好处是,对于整个搜索过程中后续高保真度的评估运算,可以建立在前面低保真度的评估计算结果的基础上,这样更节约了资源,没有浪费前面的开销/尝试(左图-红框)
-
(右图)实现了一些联邦下的HPO算法,使得实现上更为简单,容易使用作为一个插件。
-
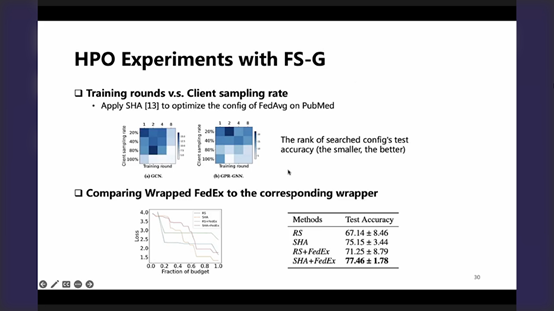
P30-相应的一些经验式的实验总结
(上图)比较了 用户采样(指示-保真度的维度)和训练轮次的关系
在著名的PubMed上,构造了一个联邦版本,用Fedavg训练,
1. 一方面,可以看到保真度越低,超参性能越差,但整体可以看到还是一个可用的,即可以比较激进的使用低保真度,这无疑可以大大的降低算例的运行时间及消耗
2. 另一方面,图中两个维度可以针对系统状态-带宽、数据分布、性质等等进行一个平衡,以期望到达一个经济的高效性/准确性的权衡。
(下图)比较了以下如FedEx(本质上做了并发的探索)这种专门针对FL设定的HPO方法,是否较之于常规HPO方法有一个更大的优势
-
从左图 regret角度来看,其并没有总是更快地搜到更好的超参配置
-
但最终结果(右图)确实相较于常规方法有一定提升
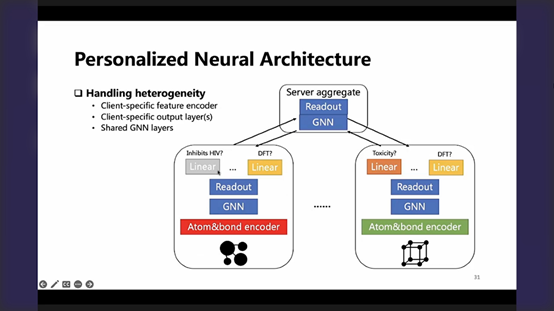

P31、32-联邦学习如何支持更加个性化的场景?框架中可以简单地设定某些不参加联邦聚合的元素,为其独有,在server同client的通信中会被过滤掉……更进一步(略)….
视频2卡的很,声音一顿一顿,看不下去,是回答了8个问题,没听.
总结:导出了PPT,作者的思路很明确,解释中的名词也是论文中出现的,如不考虑细节,大致可以明白具体是干了什么,视频2很卡,没看成,8个问题没听到,这是一个遗憾!!!后续可以先介绍FederatedScope-GNN,再走入对联邦学习的介绍,再以作者分享的这个为骨架,填充相关知识(作者的讲解,增强了对文章的了解,对于那些看不懂的部分,也明白了是为了干什么的,对于论文中的实验内容,我是没看到,作者这里给出了实验结论,是极好的!
10/30/2022 6:06:01 PM