做的到的叫想法,做不到的叫空想。
分类目录归档:Uncategorized
学习:联邦学习框架-概念与思想-2
Federated Learning Challenges, methods, and future directions
前人笔记:https://blog.csdn.net/liuzeyao_Newton/article/details/127027990
文章链接:https://ieeexplore.ieee.org/abstract/document/9084352/
文章的论述入手点:边缘计算-分布式系统(注:以下仅用于学习记录!!!)
分布式网络中的设备的计算能力不断增强,加之对隐私信息的担忧,使得本地存储数据并将网络计算推到边缘越来越有吸引力。
联合学习有潜力在不降低用户体验或泄露私人信息的情况下实现智能手机上的预测功能。
相较于传统分布式计算,后者需要在隐私、大规模机器学习和分布式优化等领域取得根本性的进步,并在机器学习和系统等不同领域的交叉领域提出了新的问题。
具体应用:下一个单词预测器、医院等隐私性要求高的系统、打破隐私问题对物联网设备连接的限制。
标准的联邦学习问题:涉及从存储在数千万甚至数百万个远程设备上的数据学习单个全局统计模型。我们的目标是在以下约束条件下学习这个模型:设备生成的数据在本地存储和处理,只有中间更新定期与中央服务器通信。目标通常是最小化以下目标函数:
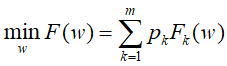
m表征设备数目,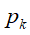 表征各设备的权重,
表征各设备的权重,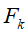 表征第k个设备的本地目标函数。
表征第k个设备的本地目标函数。
关键挑战:
-
更高的通信开销:1.减少通信轮次 2.较少通信流量
-
系统的异构性(设备性能不同,设备并非同时在线运行、连接或能量限制使得预想的处理任务不一定能完成):1.算法运行的低预期 2.对异构设备的容忍 3.通信网络中的设备失联
-
统计数据的异构性:
(此处内容说明,注意从数学/建模角度,该方案并非唯一解,且存在着相应的问题,需要仔细分析)Devices frequently generate and collect data in a highly nonidentically distributed manner across the network, e.g., mobile phone users have varied use of language in the context of a next-word prediction task. Moreover, the number of data points across devices may vary significantly, and there may be an underlying statistical structure present that captures the relationship among devices and their associated distributions.
这种数据生成范式(不同设备间的用户差异)违反了分布式优化中经常使用的独立和同分布(i.i.d)假设,并可能增加问题建模、理论分析和解决方案的经验评估方面的复杂性。
而针对单一全局优化模型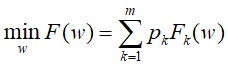 ,相应还有其他替代方案,例如通过多任务学习框架同时学习不同的局部模型。类似问题:metalearning:Differentially private meta-learning Learning:https://arxiv.org/abs/1909.05830
,相应还有其他替代方案,例如通过多任务学习框架同时学习不同的局部模型。类似问题:metalearning:Differentially private meta-learning Learning:https://arxiv.org/abs/1909.05830
-
隐私问题:就算仅交流模型更新信息,仍然会向第三方或中央服务器透露敏感信息,即便是secure multiparty computation (SMC),differential privacy这类算法,但这些方法通常以降低模型性能或系统效率为代价,这将带来取舍与权衡(tradeoffs)。
相关研究及当前工作:
同类看似相似的问题处理方法,在联邦学习框架中适用性存疑,其面临的问题不可忽略。(文中提到:联邦学习框架的规模、异构性、基于统计-平均处理的隐私保护在系统统计特性变化时并不能明确保证)考虑如下几点:(略去具体细节,略去其所提及的现实依据及存在的问题,仅表述其思想,具体请细看原文)
如下表述的思想,可能是源自已有的分布式系统实践、也可能是数据中心的集中训练中的实践,任何的改进,一者是看新问题带来了什么,二者是看如何将旧有的知识加以兼容运用。--感想
-
通信效率 :
-
局部更新算法(eg.FedAvg算法)
-
削减单次的计算量-如利用凸优化的思想,将大问题转为多个可单独处理(多轮次运及可并行运算)的子问题,以减少通信时的数据量;
-
各设备的模型更新信息先用于本地更新,多轮后再上传服务器,降低通信频次
-
-
数据压缩方案 稀疏矩阵、损失滤波
-
分散训练 以服务器为中心的星形网络,可以改为相邻节点组成的分布式网络
-
-
系统的异构性(Systems heterogeneity)-星形网络下讨论
-
异步通信:同步方案简单,保证了串行等效计算模型。但是在系统变化时,也更容易失联设备的影响;异步方案可以减轻异构环境中的设备失联问题,但是也依赖于有界的延迟假设(在联邦学习,这个过程可能很长,以至于界限不可设置)来控制过时的程度。
-
主动采样:主动、积极地进行算法的每轮运算,可用于确定系统的参与用户、增加每轮算法处理的有效性(确保更多的参与)
-
容错:对故障设备的数据舍去/选择条件更好的设备,利用编码算法代入冗余以抵抗错误(然而由于隐私限制和网络规模,跨设备共享数据/复制通常是不可实现的)
-
-
统计学异质性(Statistical heterogeneity 数学问题,需细看原文及参考文献)
-
建模异构数据 对统计异质性进行建模(元学习、多任务学习),仅限于凸目标;
将星形拓扑建模为贝叶斯网络,并在学习期间执行变分推理。空预处理非凸模型,但是推广到大型联邦网络是昂贵的。考虑准确度以外的问题(比如公平性)很重要。
-
非独立同分布数据的收敛性保证 提出了FedProx,是FedAvg的广义的、重新参数化的版本。还有一些方法旨在通过共享本地设备数据或某些服务器端代理数据,来解决统计异质问题,但是不实际,违背了联邦学习的密钥隐私假设。
-
-
隐私(Privacy)
作为训练过程一部分的模型更新信息,也可能泄露敏感的用户信息:例如. Carlini等人证明,人们可以从针对用户语言数据训练的循环神经网络中提取敏感的文本模式,例如,特定的信用卡号码。https://www.usenix.org/system/files/sec19-carlini.pdf
-
回顾机器学习中的隐私研究(大规模机器学习场景中会带来大量额外的通信和计算成本)
具体见链接,细节太丰富了
-
Homomorphic Encryption https://www.zhihu.com/question/27645858
-
Secure Function Evaluation(SFE) or Multiparty Computation(SMC) https://blog.csdn.net/WuwuwuH_/article/details/121330076
-
在联邦学习中的隐私研究
通常可分为全局隐私和本地隐私:全局私密性要求在每一轮生成的全局模型更新信息对除中央服务器之外的所有不受信任的第三方都是私有的,本地私密性进一步要求本地模型更新信息对服务器也是私有的。
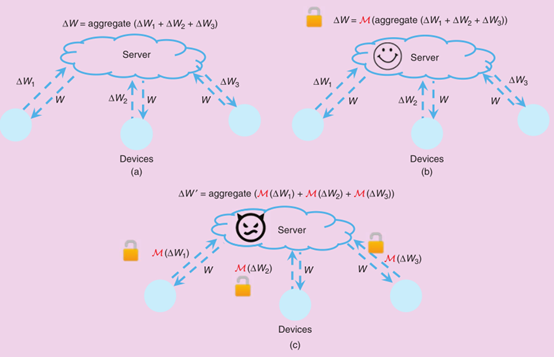
联邦学习中不同的隐私增强机制的说明。M表示用于私有化数据的随机机制。图(a)没有附加隐私保护机制的联邦学习,图(b)全局隐私-假设有一个受信任的服务器,(c)本地隐私-中心服务器可能是恶意的。
10/21/2022 9:28:33 PM
未来的发展方向:
围绕着前面所讨论挑战和一些其他的说明。
-
极端的通信方案:以确定联邦学习框架下的系统的必要通信下界,寻找最优方案(技术)
-
新的异步通信模型:在联邦网络中,每个设备通常都不是专用于手头的任务,且设备在模型算法的迭代中不一定都处在连接状态。因此,值得研究这种更现实的以设备为中心的通信方案的效果,在这种方案中,每个设备自身可以决定何时"唤醒",这时它从中心节点提取一个新任务并执行一些本地计算。
-
异构性诊断:相较于利用本地/局部不相似来度量统计异构性,然而这些指标在没有训练之前无法定义,由此便可以引出如下问题:
-
Do simple diagnostics exist to quickly determine the level of heterogeneity in federated networks a priori
-
Can analogous diagnostics be developed to quantify the amount of systems-related heterogeneity?
针对单个设备,简单而易行的评判标准,可以解决大规模设备连接情况下的算法局部/全局模型更新信息的采用与否问题(若是过于异质的数据点,应当加以舍去,如何舍去,又成了一个问题)
-
Can current or new definitions of heterogeneity be exploited to design new federated optimization methods with improved convergence, both empirically and theoretically?
新问题,往往都是带有两面性,一面是旧技术的兼容,一面是解决的新思路。
-
Granular privacy constraints:不同的设备之间的特异性,也标志着相应隐私的特异性,利用样本对用户原隐私数据采样,样本数据的用户隐私性会下降,而模型也可得到足够多的数据;此外,不同设备的隐私约束也不一定相同,如何灵活地针调整、设置隐私限制,更精细化的隐私区分也许是一个方向。
-
监督学习之外:
什么是无监督学习?-最好举出常见的 有监督学习 和 无监督学习 的算法https://www.zhihu.com/question/23194489/answer/2614496341
其提及上述的讨论都大致可以归于设备用户对于一个已知模型的优化更新,有着明确的运算目标,其期望着各设备用户都有着相同"标签"的数据,而实际中的用户数据也许特异性超过了"标签"的界定;或者说,如何利用"弱标签"的用户设备数据,去探索、似无目的去寻找,发现,也许是联邦学习的另一个有趣的前景。(上边链接提及 监督/无监督学习,可以作为参照解释)
-
-
Productionizing federated learning
实际生产使用中,concept drift 概念漂移(底层数据所生成模型随时间发生变化)、昼夜变化(设备在一天或一周的不同时间表现出不同的行为)及自身问题(如网络中增加新的设备)都需认真处理。
提供了一个参考文献:https://proceedings.mlsys.org/paper/2019/file/bd686fd640be98efaae0091fa301e613-Paper.pdf
-
未来的发展方向:
该文章概述了联邦学习,定义其为分布式网络中对统计模型进行边缘训练的一种学习模式。从传统分布式计算角度出发,分析讨论联邦学习的特性及相关挑战。
。我们提供了关于经典算法的广泛调研,以及更近期的专门关注联邦设置的工作。概述了一些值得未来研究的开放问题。为这些问题提供解决方案将需要多的研究团体的跨学科努力。
-----
Federated Learning Challenges, methods, and future directions-----完毕
联邦学习/联盟学习 (Federated Learning) 的发展现状及前景如何?https://www.zhihu.com/question/329518273 (推荐,看看公司在干什么!)
10/22/2022 10:03:27 PM